
為什麼「同一份資料」會講出兩個故事?
生物統計如何在偏差、干擾與機運中,把流行病學觀察翻譯成可決策的健康證據。
為什麼「同一份資料」會講出兩個故事?
某縣市衛生局發布一份新聞稿:去年推動的社區篩檢計畫,參與者的大腸癌死亡率比未參與者低了 30%。聽起來像是篩檢的勝利。但在隔壁的公衛系研討室裡,一位研究生看著同一張表,皺起了眉頭:參與篩檢的人本來就比較注重健康、比較常運動、比較少抽菸——這 30% 究竟有多少來自篩檢本身,又有多少只是因為「會去篩檢的人本來就比較健康」?
這就是生物統計(biostatistics)真正要回答的問題。它不只是把數字算出來,而是要在充滿雜訊、偏差與機運的真實世界裡,判斷一個健康現象到底是「真的」還是「碰巧」,並且把不確定性老老實實地量化出來。對公共衛生來說,這件事攸關政策資源該往哪裡投、哪個族群該優先介入、一項介入措施值不值得推廣到全國。換句話說,生物統計是把臨床與流行病學的觀察,翻譯成可以決策的證據的那道橋。
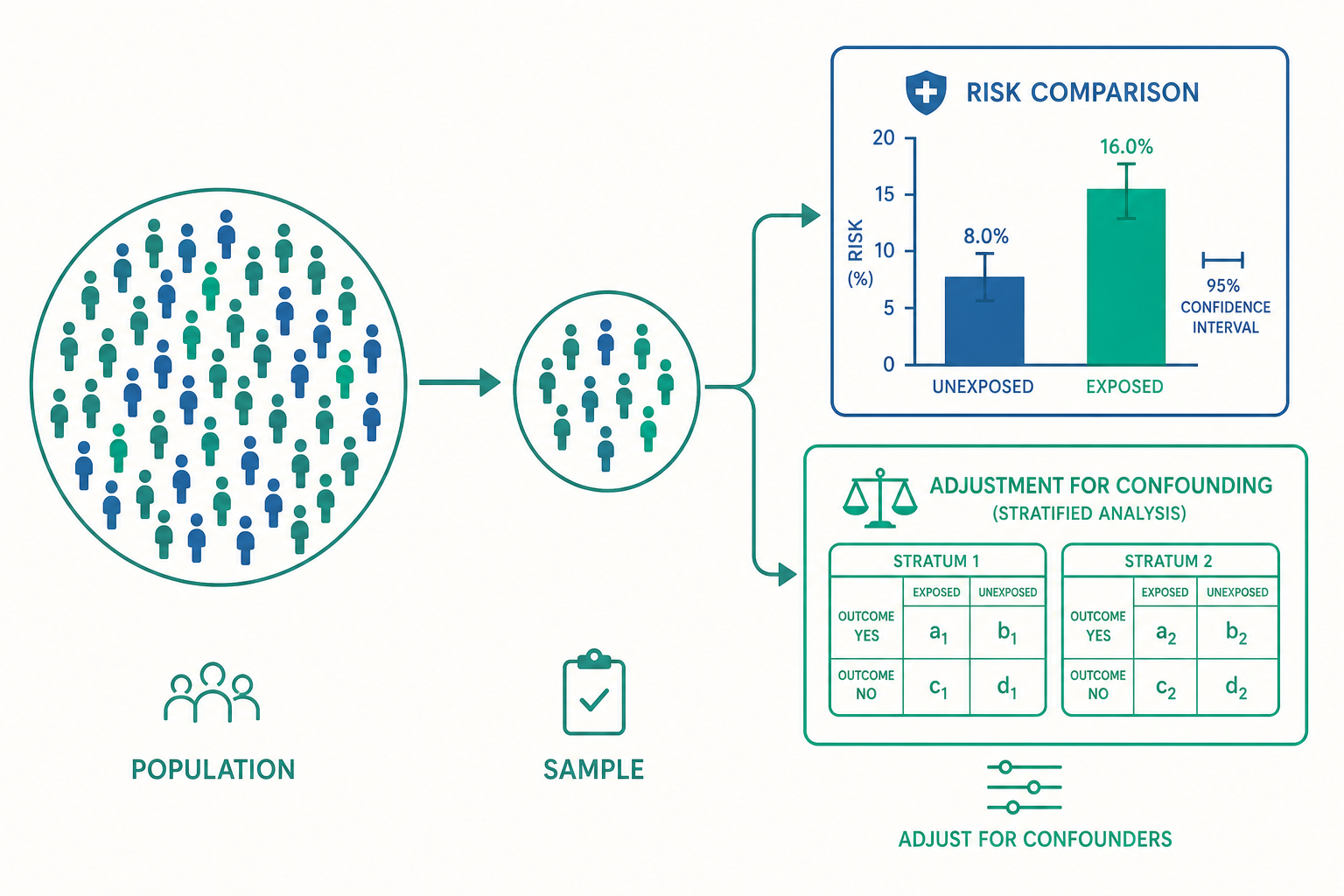
從個體到族群:生物統計的提問方式
在優統計裡,你已經熟悉了平均數、標準差、抽樣分布與假設檢定這些工具。生物統計並沒有發明全新的數學,它的特殊之處在於研究對象與提問方式:我們關心的不是單一個人,而是一個族群(population)的健康狀態,以及暴露(exposure)與結果(outcome)之間的關聯。
一個典型的公衛問題長這樣:「居住在主要幹道 100 公尺內的居民,氣喘發生率是否高於距離較遠的居民?」這裡有幾個生統的核心元素:
- 暴露變項:是否住在幹道附近(空氣污染代理指標)。
- 結果變項:是否罹患氣喘。
- 族群:某地理區域的所有居民,而我們只能觀察到其中一個樣本(sample)。
- 目標:從樣本推論回族群,並評估這個關聯有多可靠。
因為公衛資料幾乎都來自觀察而非實驗(你不可能隨機指派某些人「住在污染區」),所以生物統計從一開始就必須與偏差(bias)和干擾(confounding)正面交鋒。這也是它和一般統計學最大的氣質差異:純統計問「這個關聯在資料裡是否顯著」,生物統計則進一步追問「這個關聯是否反映了真實的因果機制,還是被其他因素污染了」。
描述健康:率、比與測量尺度
在做任何檢定之前,公衛人要先學會「正確地描述」一個族群的健康狀態。這裡有三組常被混淆的概念。
盛行率(prevalence)與發生率(incidence)。 盛行率是某一時間點,族群中「現有」病例的比例,像是「2025 年某市成年人糖尿病盛行率為 11%」——它回答「現在有多少人病著」。發生率則是一段期間內「新發生」病例的速率,像是「每千人年新增 5 例」——它回答「疾病產生的速度有多快」。盛行率受病程長短影響(病人活得久,盛行率就高),發生率才真正反映風險。把兩者混用,是公衛報告中最常見的錯誤之一。
相對風險(relative risk, RR)與勝算比(odds ratio, OR)。 這兩個是流行病學量化關聯的主力指標。相對風險是暴露組的發生率除以非暴露組的發生率:RR = 2 代表暴露讓風險變成兩倍。勝算比則是用「勝算(odds)」相除,常見於病例對照研究(case-control study),因為在這種設計下無法直接算發生率。當疾病罕見時,OR 會近似 RR;但當疾病常見時,OR 會把效應誇大,這是解讀時必須警覺的陷阱。
測量尺度決定方法。 變項是類別(性別、血型)、順序(教育程度)、還是連續(血壓、BMI),直接決定你能用哪種統計方法。把連續血壓硬切成「高/正常」兩類,雖然方便溝通,卻會丟失資訊、降低檢定的統計檢力(statistical power)。這是初學者常踩的雷:分類不是免費的,它有資訊代價。
機運的角色:信賴區間與 p 值
回到開頭那個 30% 的故事。假設我們已經(暫時)排除了偏差,剩下一個問題:這 30% 的差距,會不會只是抽樣的機運造成的?
這正是統計推論(statistical inference)要處理的。公衛裡有兩種互補的表達方式:
p 值(p-value) 回答:「假如暴露與結果其實毫無關聯(虛無假設成立),那麼我們觀察到目前這麼極端、甚至更極端的結果的機率有多大?」p 值小(慣例上 < 0.05),代表「在沒有關聯的假設下,這個資料很難出現」,於是我們傾向拒絕虛無假設。但請特別注意:p 值不是「關聯為真的機率」,也不是「效應大小」。一個 p = 0.001 的關聯可能在臨床上微不足道;一個 p = 0.06 的關聯也可能極其重要卻因樣本太小而未達顯著。
信賴區間(confidence interval, CI) 則更受現代流行病學青睞,因為它同時傳達了效應大小與精確度。一個「RR = 1.8(95% CI:1.2–2.7)」告訴你:點估計是 1.8 倍風險,而且這個區間不包含 1(無關聯的值),所以達到統計顯著;區間頗寬,反映樣本還不夠大。95% CI 的正確詮釋是:「若以同樣方法重複抽樣多次,約 95% 的區間會涵蓋真值」——它描述的是程序的長期表現,而非「真值有 95% 機率落在這個區間」。
公衛實務上有一個重要原則:不要只看 p 值的星號,要看效應大小與區間。 一個達到顯著但 CI 緊貼著 1(如 1.01–1.05)的關聯,對族群健康的實質意義往往有限。
看一個例子:兩個社區的腸道感染率
假設你在調查兩個社區的某腸道感染。社區 A 自來水加氯,社區 B 使用未處理的井水。一年下來:
- 社區 A:2000 人中有 40 人感染,發生率 = 40 / 2000 = 2.0%。
- 社區 B:1500 人中有 90 人感染,發生率 = 90 / 1500 = 6.0%。
相對風險 RR = 6.0% / 2.0% = 3.0。井水社區的感染風險是加氯社區的 3 倍。
接著我們想知道這個差距是否可能只是機運。對兩組比例做卡方檢定(chi-square test),或計算 RR 的 95% 信賴區間。假設算出 95% CI 為 2.1–4.3。這個區間不包含 1,所以在 α = 0.05 的水準下達到統計顯著——我們有合理證據認為水源處理與感染風險有關。
但生物統計的訓練會讓你立刻多問三句:
- 兩個社區除了水源,還有什麼不同?年齡結構、衛生習慣、人口密度——這些都可能是干擾因子。
- 病例是如何被偵測的?如果社區 B 剛好有一間診所更積極通報,會不會高估了 B 的發生率(偵測偏差)?
- 這個關聯有沒有生物學上的合理性?水媒病原透過未處理井水傳播,機制清楚——這支持因果解讀。
換句話說,RR = 3.0 與顯著的 CI 只是「故事的開頭」,不是結論。
對付干擾:分層與調整
干擾(confounding)是公衛資料分析的核心難題。一個干擾因子,是同時與暴露和結果有關、又不在因果路徑上的第三變項。經典例子:研究「喝咖啡與肺癌」,可能會發現正相關,但真正的元兇是抽菸——抽菸者比較常喝咖啡(與暴露相關),抽菸也致癌(與結果相關)。咖啡只是揹了黑鍋。
生物統計處理干擾有兩條主要途徑:
分層分析(stratification)。 把資料依干擾因子分層,在每一層內各自看關聯。如果在抽菸者與非抽菸者各自的層內,咖啡與肺癌的關聯都消失了,那原本的關聯就是抽菸造成的假象。Mantel-Haenszel 方法可以把各層的估計加權合併成一個調整後的估計。
多變項迴歸(multivariable regression)。 當干擾因子很多時,分層會把資料切得太碎。這時改用迴歸模型,把多個變項同時放進去,估計每個變項在「其他變項固定」下的獨立效應。公衛最常用的兩種是:
- 邏輯斯迴歸(logistic regression):結果是二元(生病/沒病),輸出調整後的勝算比。
- Cox 比例風險模型(Cox proportional hazards model):用於存活分析(survival analysis),處理「事件發生的時間」資料,輸出風險比(hazard ratio, HR)。它能優雅地處理設限資料(censoring)——也就是追蹤期間內還沒發生事件、或中途失聯的個案。
存活分析在公衛特別重要,因為我們常關心的不只是「會不會發生」,而是「多快發生」。Kaplan-Meier 存活曲線就是描述族群隨時間「存活比例」變化的標準工具。
動手試試:辛普森悖論的陷阱
請看這組虛構但典型的腎結石治療資料。兩種療法 A、B,整體成功率:
- 療法 A:整體成功率 78%(273/350)
- 療法 B:整體成功率 83%(289/350)
乍看 B 比較好。但如果我們依「結石大小」分層:
| 小結石 | 大結石 | |
|---|---|---|
| 療法 A | 93%(81/87) | 73%(192/263) |
| 療法 B | 87%(234/270) | 69%(55/80) |
分層後,在小結石和大結石中,療法 A 都比較好!
為什麼整體反而是 B 贏?因為療法 A 被優先用在更難治的大結石(263 例 vs B 的 80 例),而大結石本來成功率就低,把 A 的整體平均拉低了。這就是辛普森悖論(Simpson's paradox)——結石大小同時影響「分到哪種療法」與「成功率」,是個強力干擾因子。如果只看整體數字,你會做出完全相反的臨床建議。
這個例子的教訓很直接:整體聚合的數字可能說謊;不調整干擾因子的關聯,可能指向錯誤的方向。 這也是為什麼公衛論文裡,你幾乎總會看到「調整後(adjusted)」的估計值。
樣本要多大?檢力與型一、型二錯誤
在規劃一項公衛研究時,「要收多少樣本」是繞不開的問題。樣本太小,就算真有效應也檢測不出來,浪費資源與受試者的善意;樣本過大,則可能把毫無實質意義的微小差異也判為顯著。
這裡有兩種會犯的錯:
- 型一錯誤(Type I error, α):虛無假設其實為真,卻被我們錯誤地拒絕——也就是「無中生有」,宣稱有關聯但其實沒有。慣例上控制在 0.05。
- 型二錯誤(Type II error, β):虛無假設其實為假,我們卻沒能拒絕它——「視而不見」,真有關聯卻沒檢測到。
統計檢力(power)= 1 − β,是「當效應真的存在時,研究能成功偵測到它的機率」。公衛研究設計通常要求檢力至少 80%。檢力受四個因素拉扯:效應大小、樣本數、變異程度、與顯著水準。在規劃階段做樣本數估算(sample size calculation),就是在這四者間取得平衡,確保研究「值得做」。
一個常被忽略的觀念是:未達顯著(p > 0.05)不等於「沒有效應」。它可能只代表「這份資料的檢力不足以偵測到效應」。把「沒有證據顯示有差異」誤讀成「有證據顯示沒有差異」,是公衛溝通中相當危險的一種誤解。
重點回顧
- 盛行率反映「現在病著的比例」,發生率反映「疾病產生的速度」;前者受病程長短影響,混用會誤導。
- 信賴區間比 p 值資訊更豐富:它同時告訴你效應大小與精確度。p 值小不代表效應大,未達顯著也不代表沒有效應。
- 干擾因子是觀察性研究的頭號敵人;透過分層、Mantel-Haenszel、或多變項迴歸來調整,才能逼近真實關聯。
- 辛普森悖論提醒我們:整體聚合數字可能與分層後的結論完全相反,不調整干擾就下結論很危險。
- 充足的統計檢力(通常 ≥ 80%)是研究值得做的前提;樣本數估算應在研究開始前完成,而非事後補算。
深入探討(研究所視角)
走到研究所層級,生物統計的重心會從「方法的操作」轉向「因果推論(causal inference)的邏輯基礎」。觀察性公衛資料的核心困境,可以用 Rubin 的潛在結果框架(potential outcomes framework)精確表述:對每個人,我們想比較「他暴露時的結果」與「他未暴露時的結果」,但現實中每人只能觀察到其中一種——這就是因果推論的「根本問題」。族群層次的因果效應,只有在某些可辨識性假設(identifiability assumptions)成立時才能從觀察資料估計:no unmeasured confounding(無未測量干擾)、positivity(每個人都有非零機率接受各種暴露)、與 consistency。
當這些假設成立時,現代方法如傾向分數(propensity score)、逆機率加權(inverse probability weighting, IPW)、以及處理時變干擾的邊際結構模型(marginal structural models),能在標準迴歸失效之處估計族群層次的因果效應。有向無環圖(directed acyclic graphs, DAGs)則提供了一套圖形語言,讓研究者在資料分析「之前」就釐清該調整哪些變項、又該避免調整哪些——例如對撞變項(collider)若被錯誤調整,反而會憑空製造出偏差(collider bias),這正是某些「肥胖悖論」爭議的根源。
另一條重要延伸是多重比較(multiple comparisons)與可重複性危機。當一項全基因組關聯研究同時檢定數十萬個位點,沿用 α = 0.05 會產生海量的偽陽性;Bonferroni 校正過於保守,於是發展出控制偽發現率(false discovery rate, FDR)的 Benjamini-Hochberg 程序,在大規模檢定時取得更合理的平衡。這也連結到近年對 p 值的廣泛反思——美國統計學會(ASA)2016 年的聲明明確指出,p 值不應被當作科學結論或政策決策的唯一門檻。
跨領域來看,生物統計正與機器學習和因果機器學習深度融合:targeted maximum likelihood estimation(TMLE)、causal forests 等方法,試圖在保留因果解釋的同時,利用彈性模型捕捉高維資料中的複雜關係。對公衛而言,這意味著能在電子健康紀錄、穿戴裝置、環境感測等多模態資料上,估計更個人化的介入效應——這也正呼應了 Educational Omics 與健康資料整合的精神:當資料的維度與密度都在爆炸式成長,把關聯翻譯成可信因果結論的統計素養,比以往任何時候都更關鍵。
最後值得思考的是生態謬誤(ecological fallacy)與其反面原子謬誤(atomistic fallacy)的張力:族群層次觀察到的關聯(如「人均收入越高的國家平均壽命越長」)不能直接套用到個人,反之亦然。多層次模型(multilevel / hierarchical models)正是為了同時容納個體層次與族群層次的變異而生——它提醒我們,公共衛生的本質,始終是在「個人」與「群體」這兩個尺度之間,謹慎地來回對話。